In-App
Intelligence.
Your agents run where your code runs — same process, same memory, same data structures. No model server, no network seam, no vector DBs or retrieval plumbing: they share the model’s live attention, not strings shipped between services. The intelligence is part of your application — and stays yours: not on someone else’s server to be throttled, rebilled, or revoked.
Full-stack agent runtime, llama.cpp ↗ inside.
Experience it on your machine.
A private deep-research harness we built with HDK — open
source, MIT — running entirely in your terminal.
/scan PATH grounds it against files on your disk;
/web researches online, keyless by default. The runtime
makes no outbound calls and needs no keys; capabilities arrive as
AgentApps that run in-process.
From zero to a multi-agent harness in one command.
npx harness.dev my-research scaffolds a complete,
runnable harness — model, agent pool, retrieval, terminal UI.
No account, no keys, no config.
Then grow it: install pulls signed capabilities from the
channel, publish ships your own back. One CLI, scaffold
to contribute.
Apache-2.0.
harness.dev docs ↗AI as a feature, not an API call.
Boot the runtime, enable a capability, ship your own. No model server, no vector DBs, no plumbing.
import { main, call } from 'effection';
import { createContext } from '@lloyal-labs/lloyal.node';
import { initAgents, agentPool, parallel } from '@lloyal-labs/lloyal-agents';
import { reportTool } from '@lloyal-labs/rig';
main(function* () {
// The model is a file on disk. No server, no API key.
const ctx = yield* call(() => createContext({ modelPath: 'model.gguf', nCtx: 32768, nSeqMax: 8 }));
yield* initAgents(ctx);
// Five agents, one GPU batch, one shared context.
const pool = yield* agentPool({
orchestrate: parallel(questions.map(q => ({ content: q, systemPrompt: RESEARCH }))),
tools: [reportTool],
terminal: reportTool,
});
});import { RerankerCtx } from '@lloyal-labs/lloyal-agents';
import { createAppRegistry, createInMemoryConfigStore } from '@lloyal-labs/rig';
import { createReranker } from '@lloyal-labs/rig/node';
import { createWebApp } from '@lloyal-labs/web-app';
import { createCorpusApp } from '@lloyal-labs/corpus-app';
// One cross-encoder reranker feeds every AgentApp's in-the-loop retrieval.
const reranker = yield* createReranker('reranker.gguf');
yield* RerankerCtx.set(reranker);
// A capability = Source + Tools + skill + reranker, bundled. Enable it in one line.
const registry = yield* createAppRegistry({ configStore: createInMemoryConfigStore() });
yield* registry.enable(createWebApp); // keyless web research, reranked in the loop
yield* registry.enable(createCorpusApp); // your local docs
// …or install a signed one from the channel first:
// npx harness.dev install lloyal/wikipedia
// The pool reads the enabled AgentApps from context — their catalog decodes
// once into the shared spine; every forked agent inherits the toolset at O(1).
// No vector DB, no embedding pipeline, no retrieval service to run.import { Source, RerankerCtx } from '@lloyal-labs/lloyal-agents';
import { defineApp } from '@lloyal-labs/rig';
import { readFileSync } from 'node:fs';
// Implement a Source (your data + tools), point at a skill + manifest,
// and defineApp returns a validated AgentApp anyone can registry.enable.
// Same reranker, same in-the-loop admission — no vector DB, no embedding ETL.
export function* createCustomerApp() {
const manifest = JSON.parse(readFileSync('app.json', 'utf8'));
const skill = readFileSync('skill.eta', 'utf8');
const source = new CustomerSource(yield* RerankerCtx.expect());
return defineApp({ manifest, source, tools: source.tools, skill });
}// The topology is a single argument. Pool, tools, terminal stay identical.
orchestrate: parallel(tasks) // fan out — agents share the parent KV at O(1)
orchestrate: chain(steps, toStep) // sequential — each inherits prior findings in attention
orchestrate: dag(nodes) // declared — parallel where independent, serial where dependentStructured Concurrency
It's the foundation of concurrency in modern languages like Kotlin, Swift, Java (Project Loom), and C++26 — and an exact fit for GPU native agents orchestrating inference state. HDK’s TypeScript runtime uses Effection to orchestrate agent state over KV branches so every agent in a pool binds to a parent scope; cancellation propagates, teardown runs in reverse.
Continuous-Context Agents
HDK agents share GPU state, not strings. A fork is metadata-only — O(1), zero tensor copy. Child branches reuse the parent’s attention state rather than re-encoding lossy summaries. The result is 4.4× fewer tokens processed than a prompt-rebuilding approach — observed across our production traces — freeing compute for concurrent agent execution and longer retrieval loops. Active pruning keeps the context continuous. HDK gives local models what an operating system gave the CPU: processes, a scheduler, and memory management — applied to attention state.
Retrieval-Interleaved Generation
Agents don’t just retrieve — they assemble context
during generation: searching, reading, and reranking across your
app’s own data. The Source contract is the
assembly primitive — one shape for files, SQL, the web, or
user records. At every retrieval step a cross-encoder focal lens
admits only verbatim top-K chunks scoring against the
agent’s current hypothesis — bounded by token budget,
never summarized.
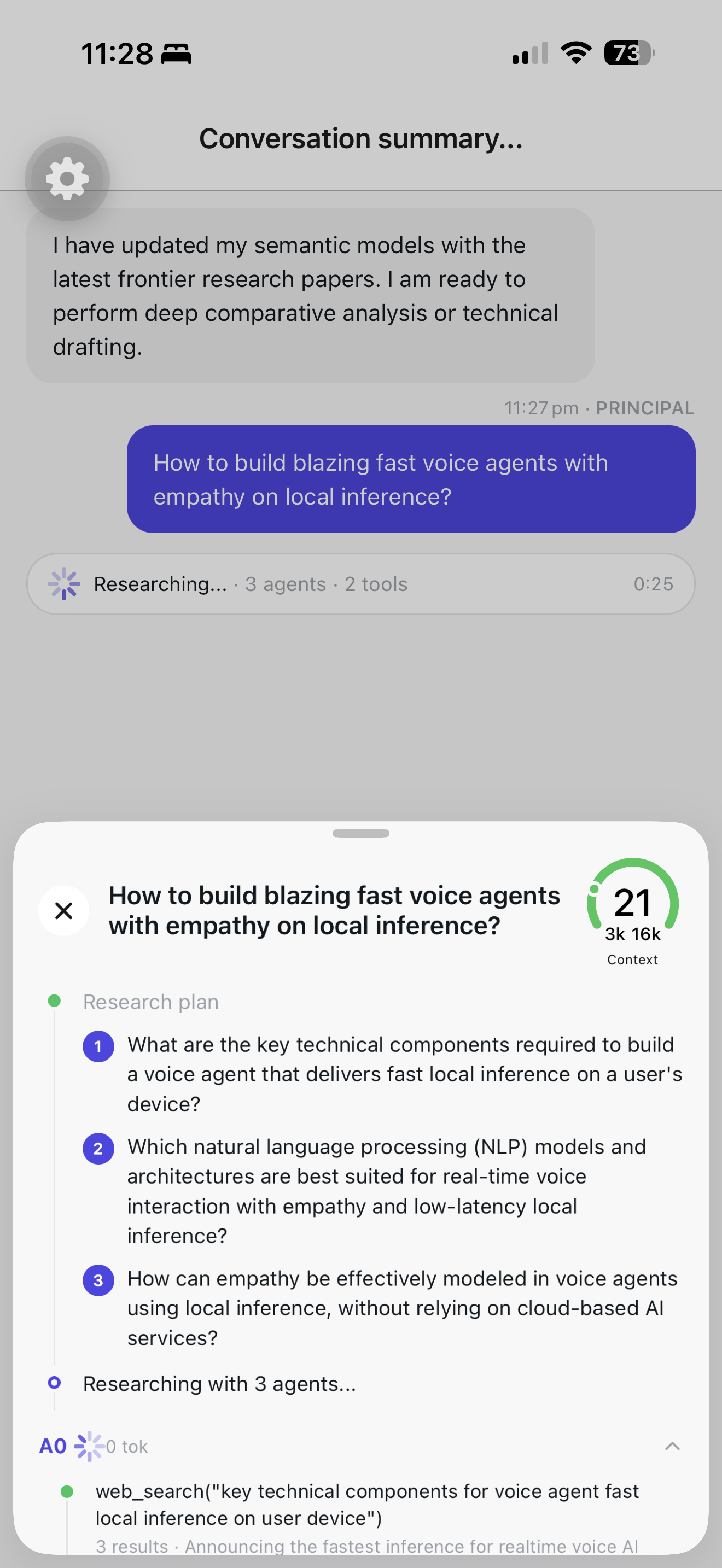
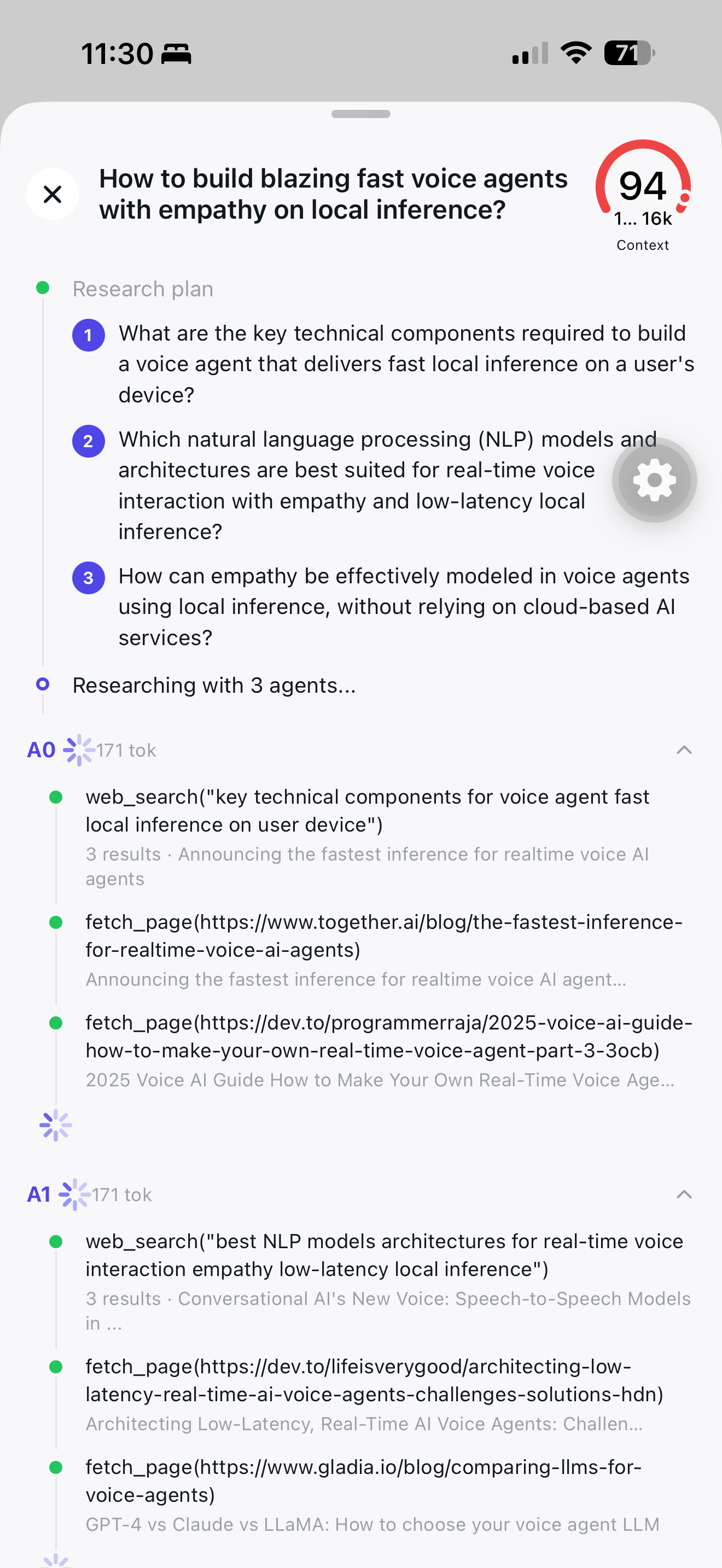
On-device. Multi-agent. Parallel.
Parallel agents running tools web_search and
fetch_page on iPhone — no API calls, no streaming
server, no cloud round-trip. The Node SDK is Fair Source
(FSL-1.1-Apache-2.0) with a full commercial grant, converting to
Apache 2.0 on a fixed schedule, and ships anywhere Node runs
— server, CLI, or desktop via Electron or Tauri. The native
iOS & Android runtime is currently in commercial preview.
Ships in your binary.
One install. Every store.
Cloud-API apps ship a UI through the store and keep the AI on someone else’s servers. With HDK, the whole product ships in one binary — agents, retrieval, inference — through every consumer channel: Mac App Store, Microsoft Store, iOS App Store, Google Play. Users click install. That’s it.
The intelligence can’t change underneath you.
The model ships in your binary — it can’t be silently retuned, throttled, or revoked, because no one else holds it. Pin the weights by hash, gate every change behind your own evals, and behaviour changes when you decide. Deterministic replay reproduces a production run with identical reasoning — the audit property a rented model can’t offer.
Sell it like software.
Price it however you want: one-time, subscription, or free. Your unit economics are uncapped — no provider takes a margin between you and your users. Your brand carries the experience, not someone else’s logo.
#include <lloyal/hdk.hpp>
// Runs on the equipment's own compute.
// Compiled native, no network in the loop.
auto pool = hdk::agent_pool({
.orchestrate = hdk::parallel(perceive, plan, monitor),
.tools = { control.dispatch_command },
.terminal_tool_name = "dispatch",
});
// Each cycle: observe, orient, decide, act.
for (;;) {
auto frame = hdk::fuse(camera, lidar, imu);
co_await pool.run(frame);
}On‑board intelligence.
Literally.
Enable the equipment you manufacture to run multi-agent Observe Orient Decide Act loops natively. No AI box, no networking overhead. Deploy models with 3D spatial reasoning that take sensor-fusion input and dispatch actuation as tool calls — autonomously, or with a human in the loop. Functional safety stays where it belongs: in your certified hardware layer. In development with launch partners, co-engineering toward 2026–2027 production cycles.
Get in touch.
Questions about the runtime, early access to the mobile build, or an OEM partnership — leave a note and we’ll reply by email.